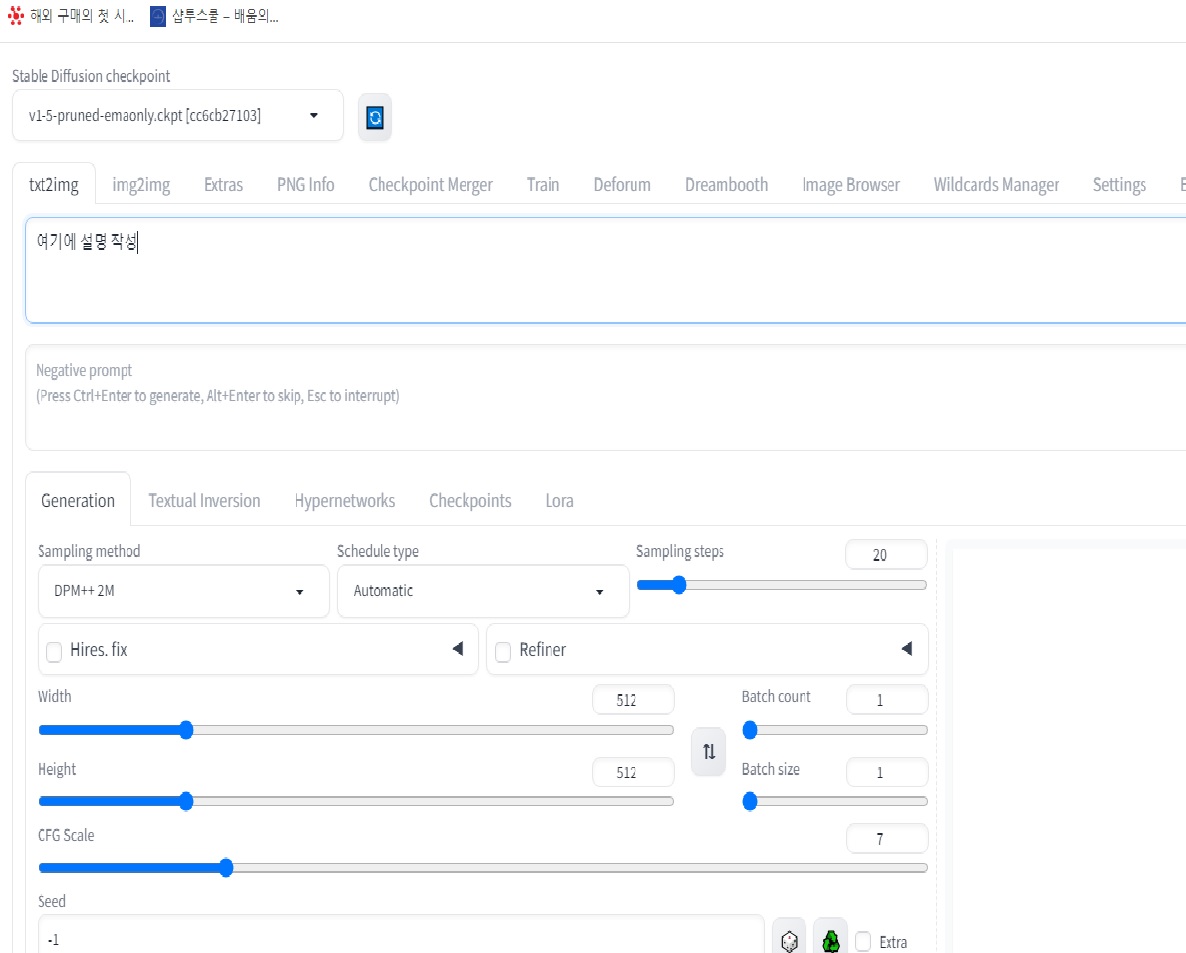
“txt2img” 옵션에 대한 사용 방법은 다음과 같습니다:
– 텍스트 입력란에 원하는 설명 또는 문장을 입력합니다.
– 설정된 다른 옵션들을 확인하고 필요에 따라 조정합니다.
– 이미지 생성을 시작하고 결과를 확인합니다.
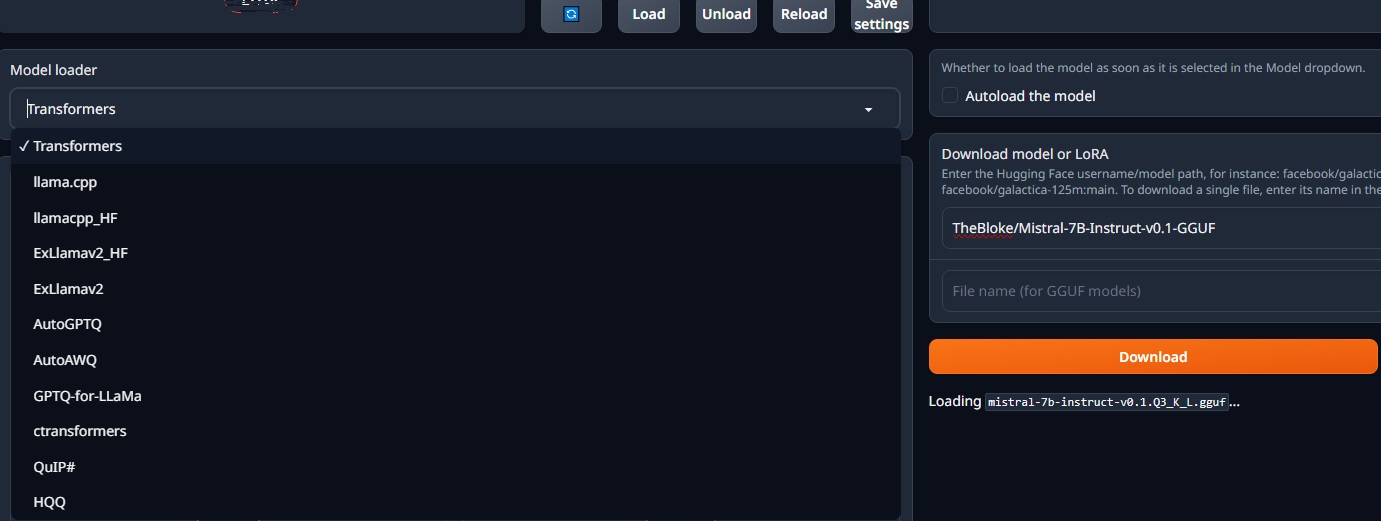
여기서는 “Stable Diffusion”의 다양한 옵션들을 설명하고, 그 중에서도 “txt2img” 옵션에 대해 설명하겠습니다.
1. **Generation**: 이미지 생성을 위한 기능을 포함합니다. 텍스트나 다른 입력을 사용하여 이미지를 생성합니다.
2. **Textual Inversion**: 이미지를 생성할 때 사용된 텍스트 프롬프트를 분석하여 이미지의 내용을 설명하는 작업을 수행합니다.
3. **Hypernetworks**: 네트워크를 학습하는 데 사용되는 기술로, 다양한 모델 구조를 자동으로 탐색하고 최적화합니다.
4. **Checkpoints**: 학습 중에 모델의 상태를 저장하는 지점입니다. 이를 사용하여 학습을 중단하고 나중에 다시 시작할 수 있습니다.
5. **Lora**: 확률적 이미지 생성 방법 중 하나로, 이미지 생성을 위한 샘플링 방법을 정의합니다.
6. **Sampling method**: 이미지 생성에 사용되는 샘플링 방법을 선택합니다.
7. **DPM++ 2M**: Dynamic Prompts를 활성화하고 샘플링 스텝 수를 지정하는 옵션입니다.
8. **Schedule type**: 학습 스케줄을 정의하는 옵션으로, 학습 속도나 다른 하이퍼파라미터를 조정합니다.
9. **Sampling steps**: 이미지 생성에 사용되는 샘플링 단계 수를 설정합니다.
10. **Hires. fix**: 해상도를 고정하는 옵션입니다. 이미지의 폭과 높이를 설정하여 생성할 이미지의 크기를 제어합니다.
11. **Refiner**: 이미지 생성에 사용되는 Refiner 모델을 설정합니다. Refiner 모델은 생성된 이미지의 품질을 향상시키는 역할을 합니다.
12. **Width**: 생성할 이미지의 너비를 설정합니다.
13. **Height**: 생성할 이미지의 높이를 설정합니다.
14. **Batch count**: 한 번에 처리할 배치의 수를 설정합니다.
15. **Batch size**: 한 배치에 포함될 이미지의 수를 설정합니다.
16. **CFG Scale**: 이미지 생성에 사용되는 스케일 계수를 설정합니다.
17. **Seed**: 랜덤 시드 값을 설정하여 이미지 생성 과정을 재현할 수 있습니다.
18. **Seed**: 이미지 생성 과정에서 사용되는 난수 생성기의 초기값을 설정합니다. 이 값은 이미지 생성 과정의 무작위성을 조절하며, 동일한 시드를 사용하면 동일한 입력에 대해 항상 동일한 결과를 생성할 수 있습니다. 값이 -1로 설정되면 시스템이 자체적으로 시드를 선택합니다.
. ?️: 주사위 아이콘은 난수 생성과 관련된 옵션을 나타냅니다. 이 아이콘은 이미지 생성 과정에서의 무작위성을 나타냅니다.
. ♻️: 재생 아이콘은 반복 가능한 프로세스를 나타냅니다. 여기서는 이미지 생성 과정을 재생할 수 있음을 나타냅니다.
19. **Extra**: 추가 기능을 지정하는 부분입니다. 여기서는 “Dynamic Prompts”, “Face Editor”, “ControlNet v1.1.445”, “ReActor”, “Regional Prompter” 및 “Script”와 같은 추가 기능이 선택되었습니다.
– **Dynamic Prompts**: 이미지 생성을 위한 동적 프롬프트를 활성화합니다. 동적 프롬프트는 이미지 생성 시 텍스트 입력을 자동으로 생성하여 다양한 이미지를 생성할 수 있도록 돕는 기능입니다.
– **Face Editor**: 얼굴 편집기를 활성화합니다. 얼굴 이미지를 수정하고 조작할 수 있는 기능을 제공합니다.
– **ControlNet v1.1.445**: 이미지 생성 과정에 사용되는 ControlNet 모델의 특정 버전을 지정합니다.
– **ReActor**: 이미지 생성에 사용되는 ReActor 모델을 활성화합니다.이 모델은 생성된 이미지의 품질을 향상시키고 이미지의 내용을 조정하는 데 사용됩니다. 주로 생성된 이미지의 세부 사항을 개선하고, 불필요한 잡음을 제거하며, 이미지의 일부를 수정하여 최종 결과물을 향상시킵니다. ReActor 모델은 생성된 이미지에 대한 후처리 작업을 수행하여 더 자연스러운 결과물을 얻을 수 있도록 돕습니다. 이를 통해 더욱 고품질의 이미지를 생성할 수 있게 됩니다.
“ReActor”라는 이름은 모델이 이미지 생성 프로세스에서 반응(Reaction)하는 역할을 수행하기 때문에 지어졌을 가능성이 높습니다. “ReActor”는 생성된 이미지에 대한 반응을 통해 이미지의 품질을 향상시키고 조작하는 역할을 합니다. 따라서 모델의 이름이 “ReActor”로 선택된 것은 이러한 반응적인 기능을 강조하고자 한 것으로 생각됩니다. 또한 “ReActor”라는 이름은 반응과 반복(Repetition)을 함께 표현하여 모델이 반복적인 프로세스를 통해 이미지를 개선한다는 의미를 내포할 수도 있습니다.
– **Regional Prompter**: 지역 프롬프터를 활성화하여 특정 지역에 대한 이미지 생성을 돕는 기능을 제공합니다.Regional Prompter”의 다음 항목에 대한 설명은 다음과 같습니다:
1. **Active**: 해당 옵션이 활성화되었는지 여부를 나타냅니다.
2. **Usage guide**: Regional Prompter의 사용 방법에 대한 안내서입니다.
3. **Generation Mode**: 이미지 생성 모드를 설정합니다.
4. **Attention**: 이미지 생성 과정에서 주의를 기울일 대상을 설정합니다.
5. **Latent**: 이미지 생성에 사용되는 잠재 벡터를 설정합니다.
6. **Base Ratio**: 기본 비율을 설정합니다.
7. **Use base prompt**: 기본 프롬프트를 사용할지 여부를 설정합니다.
8. **Use common prompt**: 공통 프롬프트를 사용할지 여부를 설정합니다.
9. **Use common negative prompt**: 공통 부정 프롬프트를 사용할지 여부를 설정합니다.
10. **Matrix**: 행렬을 설정합니다.
11. **Mask**: 이미지 생성에 사용되는 마스크를 설정합니다.
12. **Prompt**: 이미지 생성에 사용되는 프롬프트를 설정합니다.
13. **Matrix mode guide**: 행렬 모드 사용 방법에 대한 안내서입니다.
14. **Main Splitting**: 주요 분할을 설정합니다.
15. **Columns**: 열의 수를 설정합니다.
16. **Rows**: 행의 수를 설정합니다.
17. **Random**: 무작위로 설정합니다.
18. **Divide Ratio**: 분할 비율을 설정합니다.
19. **Width**: 이미지의 너비를 설정합니다.
20. **Height**: 이미지의 높이를 설정합니다.
21. **Visualize and make template**: 시각화하고 템플릿을 만듭니다.
22. **Template**: 템플릿을 설정합니다.
23. **Flip “,” and “;”**: 쉼표와 세미콜론을 뒤집습니다.
24. **Overlay Ratio**: 오버레이 비율을 설정합니다.
25. **이미지를 끌어 놓으세요 또는 클릭해서 업로드하기**: 이미지를 끌어서 업로드하거나 클릭하여 업로드합니다.
26. **Presets**: 설정 미리 지정값을 선택합니다.
27. **LoRA stop step**: LoRA 정지 단계를 설정합니다.
28. **LoRA Hires stop step**: LoRA Hires 정지 단계를 설정합니다.
29. **LoRA in negative textencoder**: 부정적인 텍스트 인코더에서 LoRA를 설정합니다.
30. **LoRA in negative U-net**: 부정적인 U-net에서 LoRA를 설정합니다.
31. **Options**: 옵션을 설정합니다.
32. **Disable convert ‘AND’ to ‘BREAK’**: ‘AND’를 ‘BREAK’로 변환하는 것을 비활성화합니다.
33. **Use LoHa or other**: LoHa 또는 다른 것을 사용합니다.
34. **Use BREAK to change chunks**: 청크를 변경하기 위해 ‘BREAK’를 사용합니다.
35. **Debug**: 디버그를 설정합니다.
36. **Debug2**: 디버그2를 설정합니다.
이렇게 다양한 옵션들을 조정하여 이미지 생성 과정을 더욱 세밀하게 제어할 수 있습니다.
– **Script**: 스크립트를 지정하여 이미지 생성 과정에 사용할 수 있습니다. 현재 여기서는 스크립트가 없음을 나타냅니다.
이러한 추가 옵션은 이미지 생성 과정을 더욱 다양하고 유연하게 만들어주며, 사용자가 원하는 이미지를 생성하기 위한 도구로 활용될 수 있습니다.