Stable Diffusion의 Wildcards Manager 탭 설명
Stable Diffusion의 Wildcards Manager 탭은 텍스트 입력 시 사용되는 와일드카드 문자열을 관리하는 데 사용됩니다. 와일드카드는 텍스트 프롬프트에서 특정 패턴을 일치하는 단어 또는 문구를 대체하는 역할을 합니다.
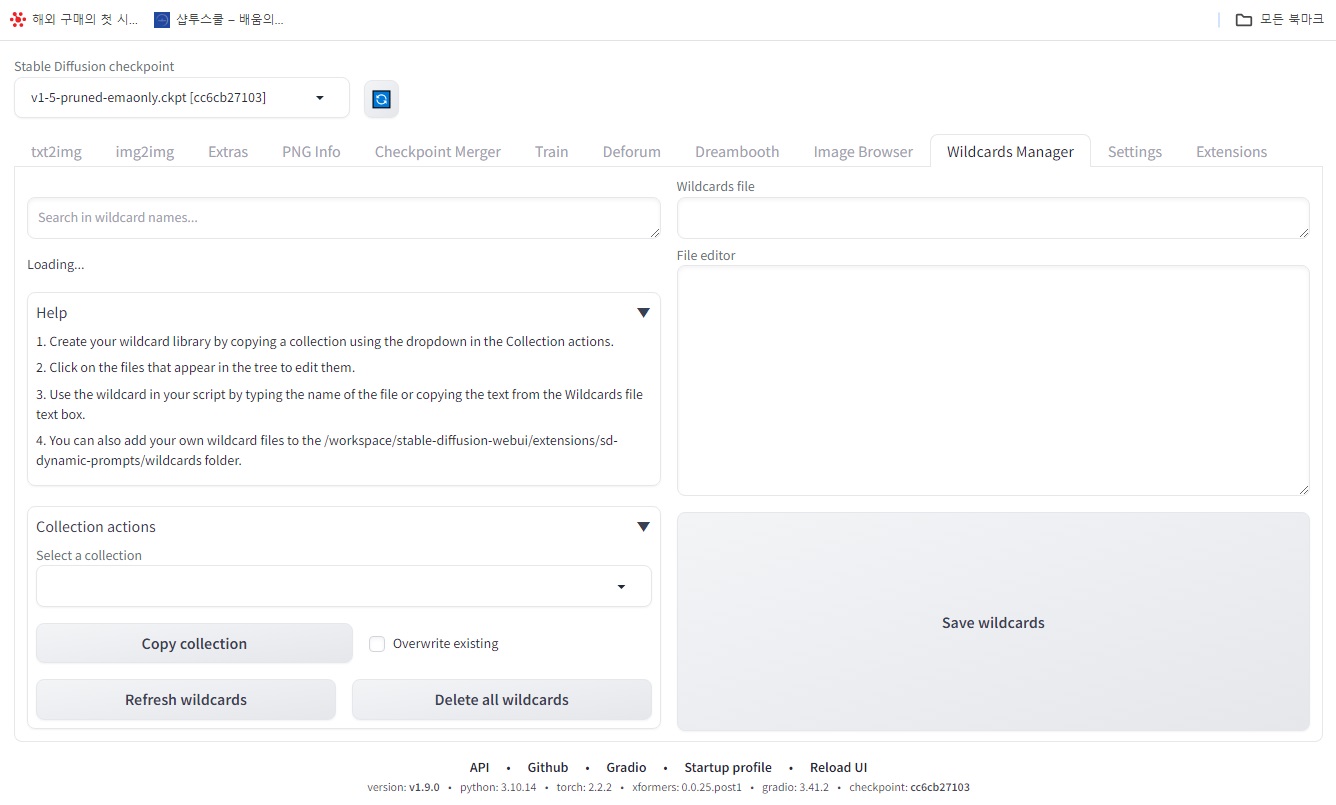
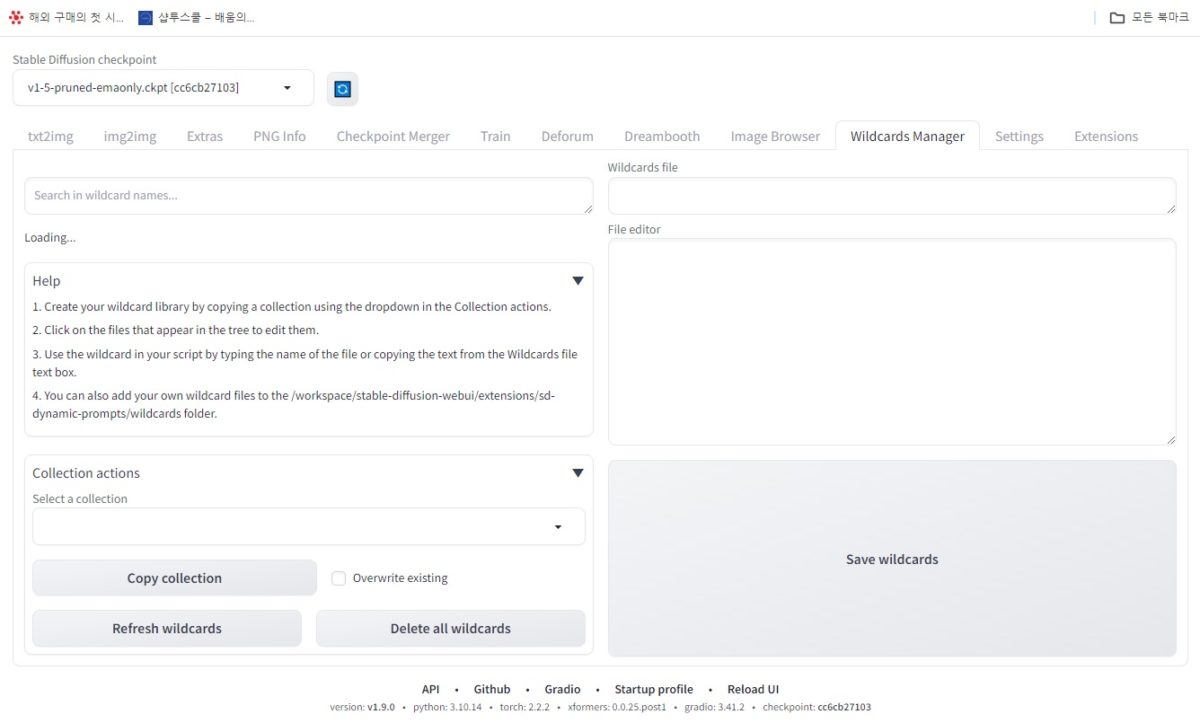
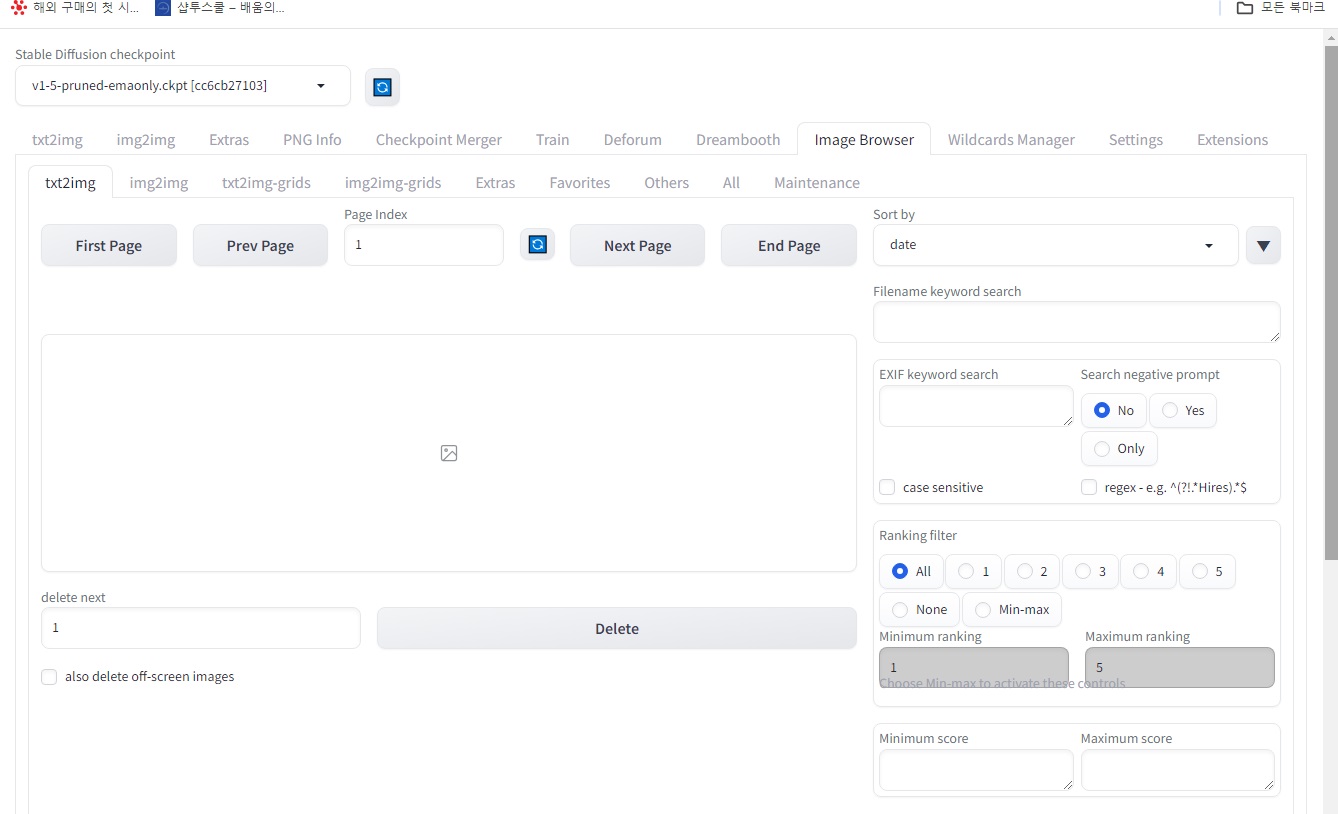
Wildcards Manager 탭 구성:
- 로드 상태 표시 (Loading…): 와일드카드 설정을 로드하는 중이라는 표시입니다.
- 도움말 버튼 (Help): 와일드카드 관리 기능에 대한 도움말 안내를 제공하는 버튼입니다.
- 컬렉션 작업 (Collection actions): 현재 로드된 와일드카드 컬렉션 전체를 대상으로 수행할 수 있는 작업 목록입니다.
- 불러오기 (Load): 외부 파일에서 와일드카드 설정을 불러옵니다.
- 내보내기 (Save wildcards): 현재 설정된 와일드카드를 외부 파일로 저장합니다.
- 지우기 (Clear Wildcards): 현재 로드된 모든 와일드카드 설정을 삭제합니다.
- 와일드카드 파일 (Wildcards file): 현재 로드된 와일드카드 컬렉션 파일 이름을 표시합니다.
- 파일 편집기 (File editor): 와일드카드 설정을 직접 편집할 수 있는 텍스트 에디터 영역입니다.
와일드카드 사용법:
- 와일드카드는 특수 문자를 사용하여 텍스트 프롬프트에서 다양한 단어 또는 문구를 나타낼 수 있습니다.
- 예시:
[animal] 은 코끼리, 사자, 호랑이 등 다양한 동물 이름을 나타낼 수 있습니다.
- Wildcards Manager 탭을 사용하여 자주 사용하는 와일드카드 패턴을 설정하고 관리할 수 있습니다.
- 와일드카드 설정은 텍스트 파일 형식으로 저장 및 불러오기가 가능합니다.
와일드카드 활용 예시:
- 동물 이미지 생성 프롬프트에
[animal] 와일드카드를 사용하여 다양한 동물 이미지를 생성할 수 있습니다.
- 객체 속성을 변경하기 위해 와일드카드를 활용할 수 있습니다. 예시:
초록색 [옷]을 입은 사람
- 배경 설정에 와일드카드를 사용할 수 있습니다. 예시:
[풍경] 앞의 자동차
참고:
- Wildcards Manager 탭의 기능은 Stable Diffusion 버전과 사용되는 확장 프로그램에 따라 다를 수 있습니다.
- 와일드카드 사용 시 구체적인 문맥과 다른 프롬프트 요소와의 조합을 고려하여 적절하게 사용해야 합니다.
Wildcards Manager 사용 예시
Stable Diffusion의 Wildcards Manager는 다양한 프롬프트 생성 작업에 활용될 수 있습니다.
**1. 특정 카테고리의 이미지 생성:**
* **목표:** 다양한 종류의 꽃 이미지를 생성
* **프롬프트:** 꽃 사진, [꽃 종류]
* **와일드카드:** `[꽃 종류]`
* **설명:** `[꽃 종류]` 와일드카드는 장미, 튤립, 수선화 등 다양한 꽃 이름을 대체하여 각 종류의 꽃 이미지를 생성합니다.
**2. 특정 스타일의 이미지 생성:**
* **목표:** 추상화 스타일의 풍경 사진 생성
* **프롬프트:** 추상화, 풍경, [색상]
* **와일드카드:** `[색상]`
* **설명:** `[색상]` 와일드카드는 빨강, 파랑, 노랑 등 다양한 색상을 대체하여 추상화 스타일의 풍경 사진을 생성합니다. 각 색상에 따라 이미지의 분위기가 달라질 수 있습니다.
**3. 특정 객체의 이미지 생성:**
* **목표:** 다양한 종류의 자동차 이미지를 생성
* **프롬프트:** 자동차, [차량 브랜드], [색상]
* **와일드카드:** `[차량 브랜드]`, `[색상]`
* **설명:** 두 개의 와일드카드를 사용하여 특정 차량 브랜드와 색상의 조합으로 이미지를 생성합니다. 예시: `페라리, 빨강` 또는 `현대, 파랑`
**4. 특정 배경과 객체의 조합:**
* **목표:** 산 앞에 서 있는 사람 이미지 생성
* **프롬프트:** 사람, 산, [옷 색상]
* **와일드카드:** `[옷 색상]`
* **설명:** `[옷 색상]` 와일드카드를 사용하여 다양한 옷 색상 (예: 빨강, 파랑, 노랑)을 입은 사람이 산 앞에 서 있는 이미지를 생성합니다.
**5. 상상력을 발휘한 프롬프트 생성:**
* **목표:** 꿈 속 풍경 이미지 생성
* **프롬프트:** 꿈, [감정], [객체]
* **와일드카드:** `[감정]`, `[객체]`
* **설명:** `[감정]` 와일드카드는 행복, 슬픔, 분노 등 다양한 감정을 표현하고, `[객체]` 와일드카드는 꿈 속에서 볼 수 있는 상징적인 대상 (예: 달, 별, 공룡)을 나타냅니다. 사용자의 상상력에 따라 무한한 이미지를 생성할 수 있습니다.
**주의 사항:**
* 와일드카드를 너무 많이 사용하면 원하는 결과를 얻기 어려울 수 있습니다.
* 와일드카드와 함께 사용하는 다른 프롬프트 요소들과의 조합을 잘 고려해야 합니다.
* 일부 와일드카드는 예상과 다른 결과를 초래할 수 있으므로 테스트를 통해 적절하게 사용하는 것이 중요합니다.
**Stable Diffusion에서 사용되는 Wildcards는 일반적인 의미의 “키워드”와는 다소 다른 개념입니다.**
**1. 일반적인 키워드:**
* 일반적인 키워드는 검색, 태깅, 분류 등 다양한 분야에서 사용되는 단어 또는 문구를 의미하며, 특정 주제나 개념을 나타내는 역할을 합니다.
* 예시: “고양이”, “축구”, “풍경” 등
**2. Wildcards:**
* Wildcards는 Stable Diffusion에서 텍스트 프롬프트 생성 시 특정 패턴을 일치하는 단어 또는 문구를 대체하는 데 사용되는 특수 문자를 의미합니다.
* 와일드카드는 프롬프트에 더 많은 유연성과 다양성을 제공하여 다양한 이미지 생성을 가능하게 합니다.
* 예시: `[animal]`, `[color]`, `[object]` 등
**3. 와일드카드와 키워드의 차이점:**
* **일반적인 키워드는 특정 주제나 개념을 직접적으로 나타내는 반면, 와일드카드는 특정 패턴을 일치하는 단어 또는 문구를 대체하는 데 사용됩니다.**
* **키워드는 검색 결과를 필터링하거나 특정 콘텐츠를 분류하는 데 사용되는 반면, 와일드카드는 이미지 생성 과정에서 다양한 요소를 조합하는 데 사용됩니다.**
**4. 와일드카드 활용 예시:**
* **”동물 사진”** 이라는 프롬프트 대신 **”동물 사진, [동물 이름]”** 와일드카드를 사용하면 고양이, 개, 사자 등 다양한 동물 이미지를 생성할 수 있습니다.
* **”풍경 사진”** 이라는 프롬프트 대신 **”풍경 사진, [색상] 하늘”** 와일드카드를 사용하면 빨간, 파란, 노란 등 다양한 색상의 하늘을 가진 풍경 이미지를 생성할 수 있습니다.
**따라서 와일드카드는 특정 주제나 개념을 직접적으로 나타내는 키워드가 아니라, 특정 패턴을 일치하는 다양한 단어 또는 문구를 대체하는 데 사용되는 도구라고 할 수 있습니다.**
Stable Diffusion의 Wildcards 활용 및 Train 탭 사용
**1. Wildcards 활용:**
* Wildcards는 Stable Diffusion의 **txt2img** 및 **img2img** 기능에서 주로 활용됩니다. 텍스트 프롬프트 생성 시 특정 패턴을 일치하는 단어 또는 문구를 대체하여 다양한 이미지 생성에 유용합니다.
* **Train 탭**에서는 직접적으로 Wildcards를 사용하지 않습니다. Train 탭은 새로운 모델을 학습하거나 기존 모델을 개선하는 기능을 제공하며, 학습 데이터 및 설정을 구성하는 데 집중합니다.
**2. Train 탭에서 Wildcards 간접 활용:**
* Wildcards를 사용하여 학습 데이터에 다양성을 추가할 수 있습니다. 예를 들어, “고양이 사진, [색상] 고양이” 와일드카드를 사용하여 다양한 색상의 고양이 이미지를 학습 데이터에 포함시킬 수 있습니다. 이는 모델이 더 다양한 이미지를 생성하도록 학습하는 데 도움이 될 수 있습니다.
* Wildcards를 사용하여 학습 데이터에 특정 스타일이나 주제를 강조할 수 있습니다. 예를 들어, “추상화, 풍경” 와일드카드를 사용하여 추상화 스타일의 풍경 이미지를 학습 데이터에 더 많이 포함시킬 수 있습니다. 이는 모델이 특정 스타일의 이미지 생성 능력을 향상시키는 데 도움이 될 수 있습니다.
**3. Train 탭에서 Wildcards 사용 방법:**
* Train 탭에서 직접적으로 Wildcards를 입력하거나 설정하는 기능은 제공되지 않습니다.
* Wildcards를 활용하려면 먼저 **txt2img** 또는 **img2img** 기능을 사용하여 원하는 이미지를 생성해야 합니다.
* 생성된 이미지를 학습 데이터에 추가할 수 있습니다.
* 학습 데이터에 Wildcards를 사용하여 생성된 이미지를 포함시키면 모델이 다양한 이미지 생성 능력을 향상시키는 데 도움이 될 수 있습니다.
**4. 주의 사항:**
* Wildcards를 학습 데이터에 무분별하게 추가하면 오히려 모델 성능을 저하시킬 수 있습니다.
* 학습 데이터에 포함시킬 Wildcards 이미지는 신중하게 선택하고 적절한 비율로 사용하는 것이 중요합니다.
* 모델 학습 과정에 대한 이해와 경험이 필요합니다.