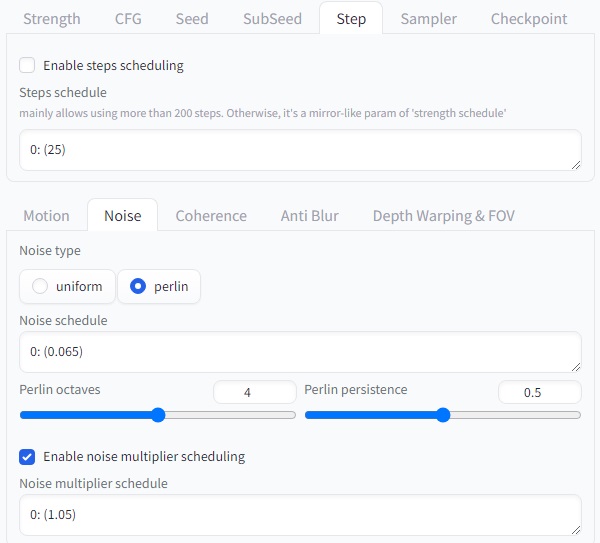
Step은 이미지 생성 과정에서 사용되는 샘플링 단계의 수를 나타냅니다. 이는 이미지의 디테일 수준을 제어하는 데 영향을 미칩니다.
**Step 설정에 대한 설명:**
– **Enable steps scheduling**: 이 옵션을 활성화하면 샘플링 단계를 조절할 수 있습니다.
– **Steps schedule**: 샘플링 단계의 수를 설정합니다. 높은 값은 더 많은 단계를 사용하여 이미지를 생성하므로 더 많은 디테일이 포착될 수 있습니다. 이는 주로 200단계 이상 사용하는 데 특히 유용합니다. ‘Strength schedule’의 거울과 같은 매개변수입니다.
이와 같은 설정을 통해 단계를 조절하여 이미지 생성 과정에서 디테일의 수준을 조정할 수 있습니다.