Stable Diffusion에서 Seed는 **랜덤 시드(random seed)**를 의미하며, 이미지 생성 과정에 사용되는 난수(random number)의 초기값입니다. Seed 값을 변경하면 완전히 다른 이미지가 생성됩니다.
Keyframes 애니메이션과 Seed
안내해 주신 정보에 따르면, Keyframes 기능을 사용하여 애니메이션을 제작할 때 Seed 옵션을 사용할 수 있습니다. 이 옵션은 애니메이션 전체 프레임에 대한 Seed 사용 방식을 제어합니다.
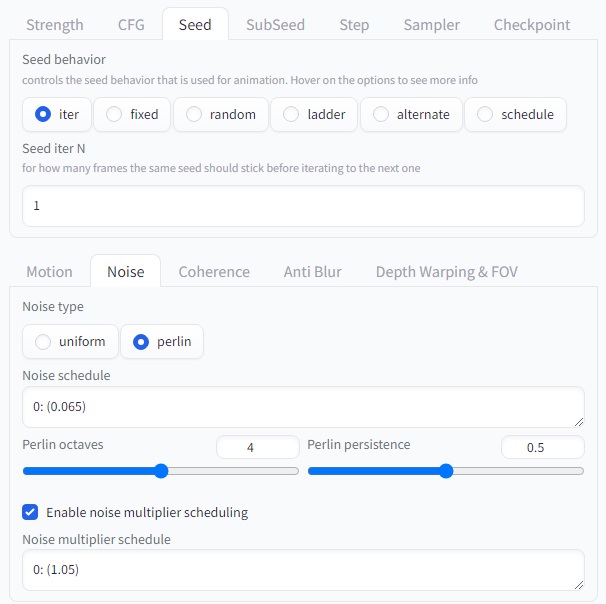
Seed behavior 옵션
- iter (반복): 지정된 프레임 수(Seed iter N) 동안 동일한 Seed를 사용합니다.
- fixed (고정): 애니메이션 전체에 걸쳐 단일 Seed를 사용합니다.
- random (랜덤): 각 프레임에 대해 랜덤하게 Seed를 생성합니다.
- ladder (계단): Seed 값을 특정 간격으로 증가시켜 매 프레임마다 미묘한 차이를 만듭니다.
- alternate (교대): 두 개의 다른 Seed를 번갈아가며 사용합니다.
- schedule (스케줄): 애니메이션 전체에 걸쳐 Seed 값을 변화시키는 스케줄을 설정합니다.
Seed iter N
이 옵션은 iter 모드에서 사용되며, 동일한 Seed를 사용할 프레임 수를 지정합니다. 예를 들어, Seed iter 5를 설정하면 처음 5개의 프레임은 동일한 Seed를 사용하여 생성되고, 6번째 프레임부터는 새로운 Seed가 사용됩니다.
다른 옵션 설명
- Motion, Noise, Coherence, Anti Blur, Depth Warping & FOV: 이 옵션들은 앞선 설명에서 다루었던 것과 동일하게 애니메이션의 움직임, 노이즈, 일관성, 선명도, 깊이 효과 등을 제어하는 데 사용됩니다.
Seed 활용 팁
- 애니메이션에서 미묘한 변화를 원한다면 iter 또는 ladder 모드를 사용해보세요.
- 완전히 다른 시각적 스타일을 원한다면 random 모드를 사용해보세요.
- 특정 시점에서 이미지의 정확성을 유지하려면 고정 Seed를 사용해보세요.
- Seed 스케줄을 사용하여 애니메이션 전체에 걸쳐 이미지의 스타일을 변화시켜보세요.
요약
Stable Diffusion의 Seed 옵션을 이용하여 Keyframes 애니메이션에서 이미지 생성에 대한 세밀한 제어가 가능합니다. 다양한 Seed 옵션과 모드를 활용하여 원하는 효과를 창출해보세요.