Stable Diffusion Extras 탭 기능 요약
Extras 탭은 Stable Diffusion에서 제공하는 다양한 이미지 처리 및 변환 기능을 한 곳에서 사용할 수 있도록 하는 공간입니다. 주요 기능들을 간략하게 요약해 드리겠습니다.
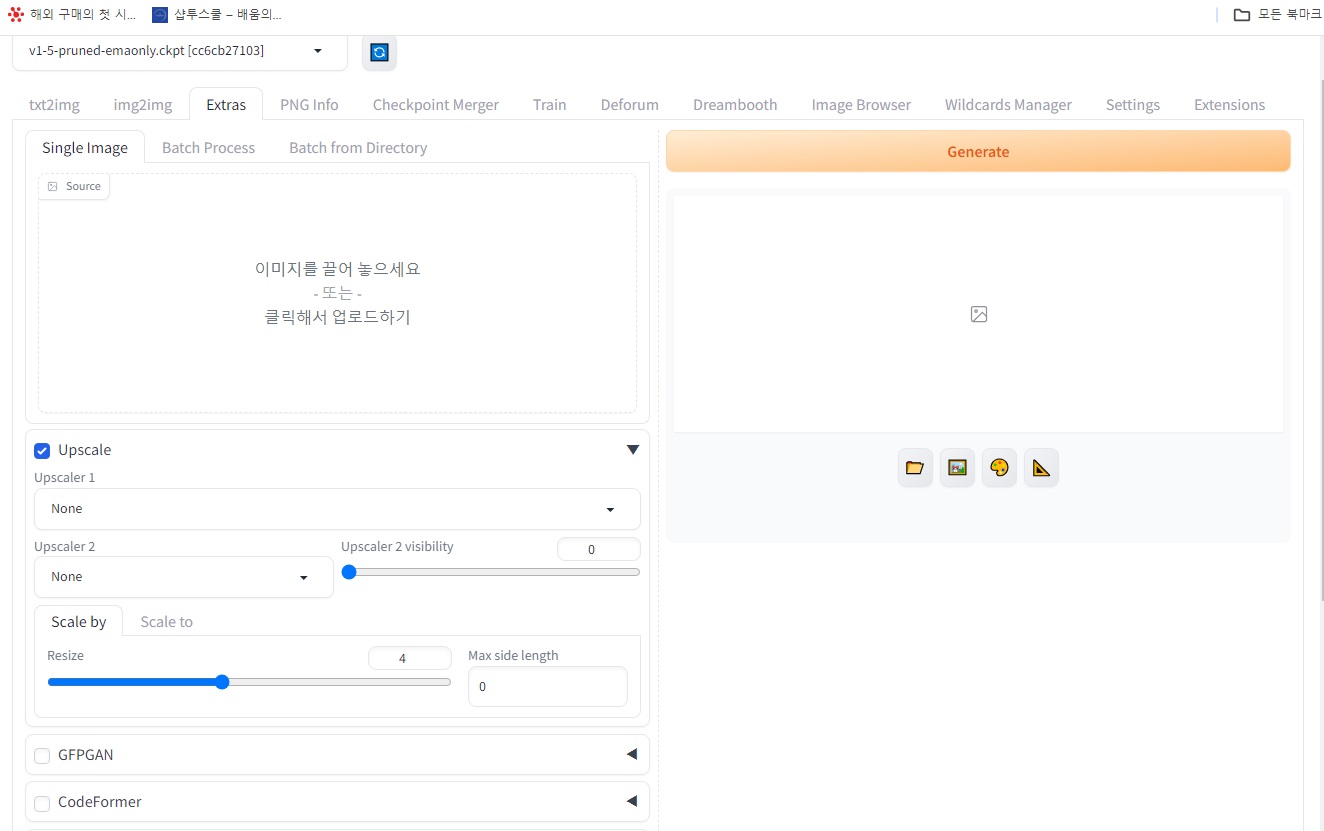
1. 이미지 처리 유형 선택:
- 단일 이미지 (Single Image): 하나의 이미지를 업로드하고 원하는 처리를 수행합니다.
- 일괄 처리 (Batch Process): 여러 이미지를 동시에 업로드하고 동일한 처리를 적용합니다.
- 디렉토리에서 일괄 처리 (Batch from Directory): 특정 디렉토리에 있는 모든 이미지를 선택하여 일괄 처리합니다.
2. 이미지 향상 및 변형:
- 업스케일 (Upscale): 이미지 해상도를 높여 선명하게 만들 수 있습니다. 다양한 업스케일러 모델 (Upscaler 1, Upscaler 2 등)을 선택하고 배율, 대상 해상도 등을 설정할 수 있습니다.
- 크기 조정 (Resize): 이미지의 크기를 원하는 크기로 조절할 수 있습니다. 최대 변 크기를 설정하여 이미지의 가로 또는 세로 길이 제한을 설정할 수 있습니다.
3. 특수 처리 기능:
- GFPGAN: 낮은 화질의 얼굴 사진을 복원하여 선명하게 만들 수 있습니다. (모든 이미지에 적용되는 것은 아니며, 사람 얼굴 이미지에 특화됨)
- CodeFormer: 이미지 처리에 CodeFormer 모델을 사용하여 다양한 효과를 적용할 수 있습니다. (모델 및 설정에 따라 결과가 다를 수 있음)
- 이미지 분할 (Split oversized images): 크기가 큰 이미지를 여러 개의 작은 이미지로 분할합니다.
- 자동 초점 자르기 (Auto focal point crop): 사람 얼굴이나 중요한 객체에 초점을 맞추도록 이미지를 자동으로 자릅니다.
- 자동 크기 조절 자르기 (Auto-sized crop): 사전 설정된 크기에 맞게 이미지를 자동으로 자릅니다.
- 이미지 반전 생성 (Create flipped copies): 이미지를 좌우 반전된 복사본을 생성합니다.
- 캡션 삽입 (Caption): 이미지에 텍스트 캡션을 삽입합니다.
4. 추가 설정:
- 각 기능마다 제공되는 추가 설정을 조정하여 처리 결과를 원하는 대로 미세 조정할 수 있습니다.
5. 이미지 업로드 및 처리:
- 이미지를 탭-앤-드롭 방식으로 업로드하거나, 파일 선택 버튼을 이용하여 업로드합니다.
- “Generate” 버튼을 클릭하여 이미지 처리를 실행합니다.
- 처리된 이미지는 탭 우측 하단의 폴더 및 갤러리 아이콘을 통해 확인 및 관리할 수 있습니다.
참고:
- Extras 탭의 기능은 Stable Diffusion 버전과 사용되는 확장 프로그램에 따라 다를 수 있습니다.
- 특정 기능 (예: GFPGAN, ReActor)은 베타 버전이거나 개발 중일 수 있으며, 변경될 수 있습니다.
- 하드웨어 성능에 따라 이미지 처리 속도가 달라질 수 있습니다.
- 이미지 처리 결과는 사용된 모델, 설정 및 원본 이미지의 품질에 따라 달라질 수 있습니다.